MiniGPT-4 : un chatbot multimodal et open source


Aujourd’hui, nous allons découvrir un nouveau modèle d’intelligence artificielle particulièrement doué, baptisé MiniGPT-4 par ses créateurs. Afin de lever toute ambigüité, et pour éviter de faire un amalgame incorrect, il convient d’apporter une précision essentielle : Mini-GPT4 n’a aucun lien avec OpenAI et n’est en aucun cas une version allégée de leur nouveau modèle GPT-4.
Si cet article commence par une présentation du modèle GPT-4 d’OpenAI, c’est qu’il y a tout de même un lien entre les deux, et bien entendu, tous ceux qui s’intéressent à GPT-4 et ses capacités multimodales trouveront certainement dans cet article et dans MiniGPT-4 un grand intérêt.
Maintenant que ces précisions ont été apportées, entrons dans le vif du sujet ! Bonne lecture…
Présentation de GPT-4 et de ses capacités multimodales
GPT-4 (Generative Pre-trained Transformer 4) est un modèle d'intelligence artificielle développé par OpenAI, éditeur du chatbot ChatGPT et de l’IA génératrice d’images Dall-E. Il constitue une petite révolution dans le domaine de l’IA principalement en raison de ses capacités d’analyse multimodale (texte + image). Contrairement aux modèles précédents, qui se limitent à l’analyse de prompts textuels, GPT-4 est capable de traiter et d’analyser à la fois du contenu textuel et des éléments graphiques.
Cela ouvre la voie à de nouveaux usages : génération de descriptions détaillées et précises d'images, génération de fiches produit, analyse de problèmes à l’aide de supports visuels, développement de sites web ou de programmes à partir de maquettes ou d'instructions écrites à la main…
Pour ceux qui auraient manqué la démonstration des fonctionnalités multimodales de GPT4, vous pouvez visionner la vidéo ci-dessous (le plus impressionnant débute à 16 minutes) :
https://www.youtube.com/live/outcGtbnMuQ?feature=share
Cependant, bien que cette démonstration soit impressionnante, peu de gens ont pu tester ces fonctionnalités d’analyse d’image. Les utilisateurs de ChatGPT plus peuvent tester le modèle GPT-4 mais uniquement avec des prompts textuels, et les développeurs qui sont passés par la liste d’attente pour accéder à GPT-4 via API n’ont eux non plus pas encore la possibilité d’inclure des images dans leurs requêtes.
De plus, même si cela peut paraître paradoxal pour une société nommée OpenAI, ses projets sont propriétaires et les sources ainsi que les données d’entraînement de GPT-4 ne sont pas publics.
Plus d’un mois après sa présentation, même une certaine impatience s’est emparée des utilisateurs quant à la mise à disposition de ces fonctionnalités multimodales de GPT-4, que ce soit dans ChatGPT ou via l’API d’OpenAI.
MiniGPT-4 : une alternative open-source prometteuse
Face à cet engouement autour de GPT-4 et à la volonté d'en comprendre davantage les mécanismes, une équipe de de doctorants de l'Université des Sciences et Technologies du Roi Abdallah en Arabie Saoudite a développé MiniGPT-4. Ce modèle open-source est capable de réaliser des tâches complexes de vision-langage similaires à celles de GPT-4, et notamment décrire le contenu d’images, et générer des réponses textuelles à partir de l’analyse d’images.
Le modèle MiniGPT-4 repose sur l'utilisation d'un Large Language Model (LLM) avancé, appelé Vicuna, pour le décodage du langage, ainsi que sur le modèle pré-entraîné de vision-langage BLIP-2 (Bootstrapping Language-Image Pre-training) pour le décodage visuel. Grâce à ces technologies, MiniGPT-4 se présente comme une alternative open-source intéressante pour explorer et comprendre les capacités exceptionnelles de GPT-4.
Le fait que MiniGPT-4 soit open-source est un avantage majeur, car il permet une plus grande accessibilité et une collaboration entre les chercheurs. De plus, étant donné que GPT-4 n'est pas encore totalement divulgué par OpenAI, MiniGPT-4 offre une opportunité unique d'étudier et de reproduire ses capacités multimodales.
Dans la suite de cet article, nous explorerons plus en détail le fonctionnement de MiniGPT-4, et analyserons ses performances et ses capacités dans le cadre de quelques tests concrets.
Test des capacités et performances de MiniGPT-4
Dans cette section, nous explorerons les différentes capacités et performances de MiniGPT-4, avec des exemples concrets issus des expériences réalisées par l’équipe de DirectIA sur la démo publique
Génération de descriptions d'images détaillées
MiniGPT-4 est capable de générer des descriptions d'images détaillées, en fournissant des informations précises sur les éléments présents dans une image et les actions qui se déroulent. Cette compétence permet de générer automatiquement des légendes ou des commentaires pour les images, ce qui peut être utile pour des applications telles que les réseaux sociaux, la création de contenu, ou encore l'accessibilité numérique pour les déficients visuels.
Quelques exemples :

L’IA a parfaitement reconnu l’assiette de sushi, et même identifié certains des ingrédients qu’ils contiennent, ainsi que la présence des baguettes.

Ici la description de l’arrière plan est très précise, en revanche l’arbre au premier plan, qui est le sujet principal de l’image analysée, a des feuilles contrairement à ce qu’indique la description générée par l’IA.
Force est de constater que MiniGPT-4 s’en sort plutôt bien et propose des descriptions relativement précises et complètes des images qu’on lui donne à analyser. L’analyse n’est pas toujours parfaitement exacte, mais c’est tout de même assez impressionnant.
Création de sites web à partir de maquettes ou de brouillons manuscrits
Une autre capacité intéressante de MiniGPT-4 est sa faculté à créer des sites web à partir de brouillons manuscrits. En analysant et en interprétant les informations contenues dans un brouillon écrit à la main, MiniGPT-4 peut générer du code HTML et CSS pour créer une interface utilisateur. Cette compétence peut être utile pour les graphistes qui pourraient ainsi réaliser des sites à partir de leurs maquettes sans savoir programmer, ou encore pour les concepteurs de sites web ou les développeurs qui souhaitent gagner du temps et de l'énergie en automatisant une partie du processus de création.
Dans les faits, nous n’avons pas été en mesure d’obtenir des résultats très convaincants sur la démo publique. Il semble que le code source généré par le modèle MiniGPT-4 soit tronqué ou mal interprété par l’interface utilisateur de la démo, ce qui rend impossible sa récupération. Mais nous avons en revanche pu voir MiniGPT-4 en action dans cet exercice dans la vidéo YouTube ci-dessous, à partir de la 50ème seconde.
https://youtu.be/__tftoxpBAw
Histoires et poèmes inspirés d'images
MiniGPT-4 peut écrire des histoires et des poèmes inspirés des images fournies. Une fonctionnalité utile pour les écrivains, les poètes ou les créateurs de contenu qui recherchent de l'inspiration ou qui souhaitent générer des œuvres originales en se basant sur des éléments visuels.
Voici un exemple, dans lequel l’IA a créé une histoire courte mais tout à fait raccord avec les éléments présents dans l’image :

Notez que nous avons volontairement monté la « température » pour cette requête afin de donner un peu plus de créativité au modèle d’intelligence artificielle.
Solutions aux problèmes illustrés par des images
En analysant les problèmes illustrés dans les images, MiniGPT-4 est capable de proposer des solutions concrètes et pertinentes. On peut imaginer énormément de cas d’utilisation : résolution d’exercices de géométrie, analyse de problèmes de la vie de tous les jours, de maladies des végétaux et même des humains à partir de photos des symptômes…
Voici un exemple dans lequel l’IA a bien identifié le problème sur l’image, et nous propose des solutions :

Au-delà de ce cas de figure inspiré des exemples fournis sur le Github de MiniGPT-4, nos différents essais concernant les cas d’usage cités plus haut ont obtenu des résultats assez variables. Et en ce qui concerne la géométrie en particulier, l’IA a souvent été mise en échec. Ses réponses indiquaient pourtant qu’elle connaissait bien les théorèmes nécessaires à la résolution des problèmes posés, mais leur application était incorrecte, même pour des problèmes très simples comme le calcul de la longueur de l’hypoténuse d’un triangle rectangle (niveau 4ème). MiniGPT-4 ne semble donc pas tout à fait au point ni dans l’analyse des formes géométriques, ni dans l’application des formules de mathématiques.
Recettes de cuisine basées sur des photos d'aliments
MiniGPT-4 peut également proposer des recettes de cuisine en se basant sur des photos d'aliments. En identifiant les ingrédients et les plats présents dans une image, le modèle peut identifier des recettes de cuisine correspondantes et indiquer la liste des ingrédients et les différentes étapes pour élaborer ces recettes.
On peut imaginer des utilisations très amusantes et utiles, comme par exemple prendre une photo du contenu de son frigo et demander à l’IA de nous donner des idées de plats que l’on peut cuisiner avec.
Pour tester cette fonctionnalité, nous avons tenté de lui donner différentes photos de desserts assez populaires et de lui demander la recette. A chaque fois, l’IA nous a proposé une recette, mais il n’a pas toujours reconnu correctement le dessert présenté. Il a par exemple plus l’île flottante pour une glace à la vanille.
Voici le résultat avec un Carrot Cake appétissant, maintenant que nous avons la recette, il n’y a plus qu’à mettre la main à la pâte, car Mini-GPT4 n’est pas encore connecté avec notre robot pâtissier !

Description du modèle et de son fonctionnement
Pour créer MiniGPT-4, les chercheurs de l'Université des Sciences et Technologies du Roi Abdallah en Arabie Saoudite ont d'abord utilisé le modèle pré-entraîné de vision-langage BLIP-2 pour encoder les informations visuelles. Ensuite, ils ont ajouté une seule couche de projection pour aligner les caractéristiques visuelles encodées avec le modèle de langage Vicuna. Les autres composants de vision et de langage ont été "gelés", c'est-à-dire qu'ils n'ont pas été modifiés lors de l'entraînement.
Technologies utilisées : Vicuna et BLIP-2
Vicuna
Vicuna est un LLM avancé construit sur la base du modèle LLaMA (Large Language Model Meta AI). Il est conçu pour le traitement du langage naturel, et donc utilisé comme décodeur de langage dans MiniGPT-4 et permet d'obtenir des performances proches de celles de GPT-4 en termes de qualité du langage généré.
BLIP-2
BLIP-2 (Bootstrapping Language-Image Pre-training) est un modèle pré-entraîné de vision-langage qui sert de décodeur visuel dans MiniGPT-4. En combinant les fonctionnalités de BLIP-2 avec celles de Vicuna, les chercheurs ont réussi à créer un modèle capable de traiter et de générer du contenu à la fois textuel et visuel, comme le fait GPT-4.
Stratégie d’entraînement du modèle
L’entraînement du modèle de langage a été réalisé en deux étapes :
- La première étape de pré-entraînement traditionnelle a été réalisée avec environ 5 millions de paires d'images-textes alignées en 10 heures en utilisant 4 processeurs graphiques A100s.
Après cette première étape, Vicuna était capable de comprendre l'image. Cependant, la capacité de génération de Vicuna n’était pas suffisamment fiable et pertinente. Pour résoudre ce problème et améliorer l'utilisabilité, l’équipe a adopté une nouvelle manière de créer des paires d'images-textes de haute qualité, avec l’aide de Vicuna et de GPT. Sur cette base, un petit ensemble de données (3500 paires au total) de haute qualité a été généré pour compléter l’entraînement. - La seconde étape d’entraînement est donc réalisée sur cet ensemble de données dans un modèle de conversation pour affiner le modèle. Cette étape, n’a pris que quelques minutes avec un seul A100, et a permis d’affiner considérablement la capacité de génération de MiniGPT-4. A l’issue, le modèle présentait des capacités de vision-langage similaires à celles démontrées dans GPT-4.
Comparaison avec GPT-4 et d’autres modèles similaires
MiniGPT-4 vos GPT-4
A ce jour, il n’existe pas à notre connaissance de comparatifs directs entre MiniGPT-4 et GPT-4. Comme nous l’avons indiqué plus haut, GPT-4 n’a pas encore été totalement publié, et la partie traitement et analyse d’images n’est connue qu’à travers les démos diffusées par OpenAI (voir la vidéo en début d’article). Il faudra donc attendre de pouvoir tester ces fonctionnalités pour pouvoir comparer effectivement les deux modèles.
Au vu des résultats observés lors de nos tests, nous pouvons quand même affirmer que MiniGPT-4 n’atteint pas le niveau de pertinence et de fiabilité minimum requis pour une utilisation professionnelle. Le fait qu’OpenAI tarde à ouvrir l’accès aux fonctionnalités d’analyse d’image de GPT-4 est probablement le signe que de leur côté aussi, le modèle nécessite encore une phase d’affinage.
Toutefois, dans la mesure où MiniGPT4 repose sur le LLM Vicuna13B, ses performances en termes de génération de langage naturel sont liées à celles de ce dernier. Et d’après un benchmark réalisé par l’équipe de Vicuna, Vicuna réalise un score quasi équivalent à Google Bard, et atteint 90% des performances de GPT-4.
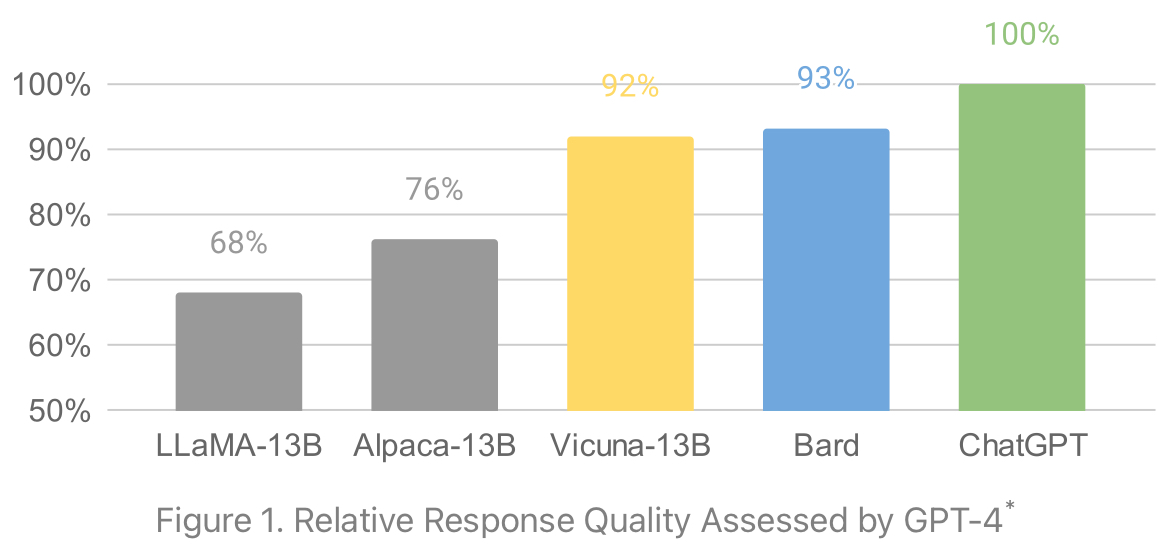
Diagramme : Performances du modèle Vicuna-13B (en jaune), utilisé par MiniGPT-4 pour la génération de textes.
Cela permet d’imaginer que le modèle MiniGPT-4 n’est probablement pas aussi performant que GPT-4 en termes de génération de langage naturel, mais qu’il se situe tout de même parmi les meilleurs modèles existants à l’heure actuelle.
Comparaison avec des modèles similaires
Le site jina.ai a réalisé un test comparatif entre MiniGPT-4 et d’autres solutions de description d’images, telles que SceneXplain et Midjourney et son outil Explain. L’objectif de ce test est d’analyser leurs performances sur l’analyse d’images complexes, sous plusieurs angles : bonne compréhension du sujet de l’image (topicality), factualité de la description, niveau de détails, et perplexité (propension à être incapable de décrire ou comprendre une image). Les résultats indiquent que MiniGPT-4 s’en sort plutôt bien en termes de niveau de détails, et de factualité. En revanche, il est un peu en retrait sur la compréhension du sujet.
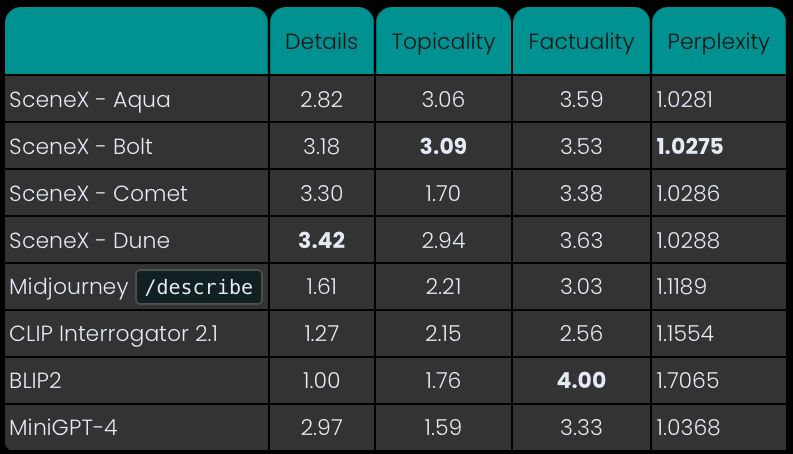
Comparatif des performances de MiniGPT-4 et d’autres modèles © jina.ai
On peut toutefois relever que ce comparatif ne concerne que la faculté à comprendre et décrire une image. Mais il éclipse les différences fonctionnelles majeures entre les différents outils comparés : la force de MiniGPT-4 n’est pas seulement de savoir comprendre et décrire une image, mais aussi et surtout, de générer des textes complexes et construits à partir de cette analyse, ce que peu d’autres outils sont en mesure de faire à l’heure actuelle.
Conclusion
MiniGPT-4 est un modèle d'intelligence artificielle multimodal très prometteur qui présente des capacités de vision-langage impressionnantes, similaires à celles de GPT-4. Grâce à ses performances et à sa nature open-source, il représente une alternative crédible à GPT-4 pour de nombreux domaines d’utilisation. C’est un projet à suivre de près, qui va contribuer à faire évoluer la recherche dans le domaine des IA multimodales.
Si vous souhaitez en savoir plus sur MiniGPT-4, il ne vous reste plus qu’à aller le découvrir par vous-même sur le site officiel : https://minigpt-4.github.io

